Entity-Component-System
A lot of the code have been stripped for display purposes, if you want the full project with more examples please visit
My Github 
Introduction
At the beginning of our second year at The Game Assembly we get the opportunity to build our own game engines, and in the previous year I got a lot of experience working in a more pure object-oriented way using GameObject component systems riddled with virtual functions causing cache misses at every function call. This ECS will have been used in a total of three games which you will be able to see here.
Having dug through the trenches and seen what problems could arise making games with a object oriented
and inheritance based model I felt a major lacking of knowledge towards a the data oriented way of programming I had seen a lot of GDC / CPPCon talks about.
The 2014 CPPcon Mike Acton talk was a huge inspiration.
Design Choices - Archetype Or Sparse-Sets
When doing research about which design choice I were to make I found there are two popularized ways to design a Entity-Component-System.
Sparse Sets
Components are stored in sparse-sets where the entity id’s map to the component.
Adding and removing components is O(1), is less complicated and faster than removing and adding components in an archetype ECS.
Archetypes
Components are stored in packed tables of contiguous memory blocks where entities and component ids act as row and column identifiers.
The archetypal pattern seemed intriguing and reading the blog posts of Sander Mertens inspired me too begin building my own.
When desiging the ECS I was deadset on keeping the user interface as simple as possible my mantra was “Every programmer on my team need to love using this tool”.
The core design pillars I employed were:
- simplicity
- safety
- speed
Core Concepts
Entity
using entity = uint64_t;
An entity is a unique identifier that represents a game object. It does not contain any data or logic itself but serves as a reference for components.
Components
Components are user created POD or Non-POD data structures that store data about an entity. Tagging entities are as simple as adding an empty component struct to the entity. This technique is used because it gives a type safe way of identifying an entity or a group of entities by using the same query system used for normal components.
Component Storage
Each Component type is stored in a column which consists of a contiguous data buffer, and type-erasure information. The type erasure information is needed because the Archetype is storing complex data types that are non POD.
class Column
{
std::unique_ptr<std::byte[]> myBuffer; //Component storage
ComponentTypeInfo myTypeInfo; //Type Info
size_t myCapacity{0}; //Amount of bytes this column can hold before needing to grow
size_t myCurrentMemoryUsed{0};
}
The Type erasure data each column hold is filled up automatically when the user calls AddComponent<T>();
Storing type-erased constructors enables the use of modern C++ functionalities, such as component holding a std::function or simply a std::string in some ECS systems only trivial data types is allowed.
I believe the reduced complexity of having the ability to store Non-POD data is strongly outweighing the negligible speed boosts of storing only POD.
struct ComponentTypeInfo
{
ComponentID typeID;
size_t size{0}; // Size of the component type in bytes
size_t alignment {0}; // Alignment requirement of the type
void (*construct)(void* aDest) = nullptr; // Function pointer for default construction
void (*copy)(void* aDest, const void* aSrc) = nullptr; // copy constructor
void (*move)(void* aDest, void* aSrc) = nullptr; // Move constructor
void (*destruct)(void* aObj) = nullptr; // Destructor
bool isTrivial = false;
}
The columns are stored in an Archetype.
struct Archetype
{
ArchetypeID myID{ 0 };
Type myType{}; //The order of components in the component list
std::unordered_set<ComponentID> myTypeSet{}; //Used for fast lookup into the archetype if it contains a specific type
std::vector<Column> myComponents{}; //Columns holding the data, use the entity row to access the specific component
std::vector<entity> myEntities{}; //serves as our entity list but the order of entities are also the rows in the component columns
std::unordered_map<ComponentID, ArchetypeEdge> myEdges{}; //Add and remove Edges.
size_t myMaxCount{0};
}
Putting the design together gives us a clever way of organizing data, empowering us to have fast lookups and fast iterations over contiguous blocks of memory with 0 data fragmentation.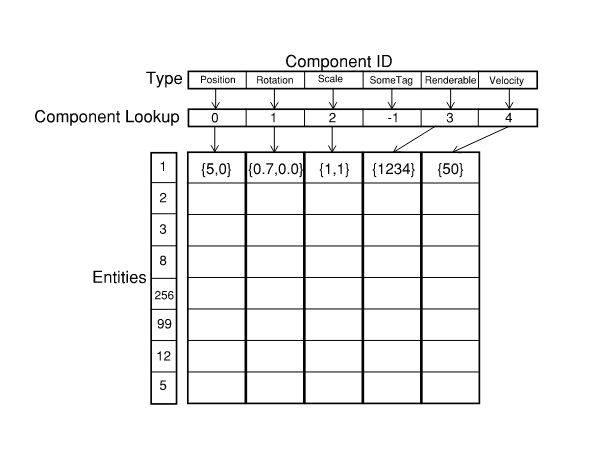
Queries
Queries are a way to quickly find every entity that match a list of component and/or tags.
QueryIterator q = world.query<Position,Rotation,Scale>();
for(Entity entity : q)
{
Position pos = entity.GetComponent<Position>();
//Do Stuff
}
The iterator stores lists of a entity ids that then lets us compose a helper class for that entity which lets us access the components of said Entity.
Since tags are empty structs its easy to add them to the query system.
Entity e = world.TQuery<PlayerTag>();
Position pos = entity.GetComponent<Position>();
Filterered queries are queries that gives us every single entity of type A,B,C.. as long as it does not contain types X,Y,Z…
This is a powerful feature that makes it easy to reason about groups of entities that we may iterate over.
For instance say that you want to stream a level, you want to destroy all entities of X,Y,Z but that query may be littered with entities that you do not intend to destroy. Tagging the entities not intended to be destroyed with <DontDestroyOnLoad> enables to filter out those entities from that query.
QueryIterator q = world.FilteredQuery<Position,Rotation,Scale,Renderable>(std::tuple<DontDestroyOnLoad>());
for(Entity entity : q)
{
//Do Stuff
}
Because every archetype is guaranteed to store every entity of that set of components, caching queries becomes as easy as storing an archetype associated with a specific query.
Systems
Systems are functions with queries.
//Systems can be added
World.system("Move Entity",[]()
{
for(Entity entity : World.Query<Position,Rotation,Scale,Velocity>())
{
Position* position = entity.GetComponent<Position>();
Velocity* velocity = entity.GetComponent<Velocity>();
position += velocity;
}
},ecs::Pipeline::OnUpdate);
//Systems can be removed
World.RemoveSystem("Move Entity",ecs::Pipeline::OnUpdate);
Removing a system puts it into a queue where it will get removed from the SystemManager at the end of the frame.
Pipelining the systems empowers every decision about the data we are operating on as we can for a fact know in what state each data is at every point of execution in our codebase.
Staging
Staging allows asynchronous management and execution of code. A stage is a new world, however this world may at any point be merged with another to resume execution in the original. This allows for example level streaming where levels and/or parts of the current level may be loaded asynchronously, code and anything else may be executed on the stage as it is essentially just another World.
SceneManager sceneManager; /example code
World.CreateStage("SomeStage");
sceneManager.loadScene();
Stage* stage = World.GetStage("SomeStage");
stage->Merge();
Here is an implementation of this I made in one of our game projects.
Player Point of View
World Point of View
Demo
Demo compiled using Emscripten and Raylib, running a simulation of Boids using a Data-oriented approach with the Entity-Component-System The demo is currently running with an algorithmic complexity of O(n^2) where each boid is testing against every other boid in the simulation.
Projects built by other people using the ECS
Physics Engine implementation by Gustaf EngsnerAI Behavior Tree implementation by Anghello Escalera
References
https://ajmmertens.medium.com/
https://research.swtch.com/sparse